As DevOps evolves, new technologies enable better processes. If your team has a process defined by tradition, take a fresh look. Use some of these examples and keep an eye out for other accelerators as time passes.
Branches for input, merges for admission, tags for output.
GitLab just released a new e-book about git branching strategies and I was writing up some thoughts on it. These thoughts turned into both a book report and my own diatribe on branching and the importance of minimalism. What follows is my diatribe with art.
Version control isn’t new
When you were finishing that report in middle school and you saved the file as The Great Gatsby_draft_4-final-really-FINAL.doc.
Since then, we have been through some stuff…
- Version files as a stream over time
- Version whole directory together
- Create thin copies or duplicates
- Multiplayer friendly
- Distributed with open source community
It will continue evolving, text management is near peak
Software to manage versions of directories full of text have been around for a long time but when git landed and blew up in the open source community, we hit peak source control. It’s not that Git is perfect, but it provides a very complete set of APIs that allow most work to happen easily and difficult things to be possible for those who choose to use it.
Since Source Code has a pretty simple cycle where the input is “text” and the output is “software” the initial focus on the output makes sense. Generating software requires a compiler. Compilers are annoying, so people built Integrated Development Environments (IDEs) to integrate the text drafting and compiler into one interface.
Why not just make the IDE do everything?
Developers started customizing IDEs and adding a lot of capabilities to them to make them autocomplete the lines of text and detect and fix errors. Even tabs and trailing spaces are no longer concerns due to helpful linters.
IDEs fail to be the central point of a DevOps workflow due the personal nature of IDEs. The experience is typically very individualized based on eyesight, short term memory, size of repos, language of choice, and everything else that makes individuals different.
When it comes to individual efficiency, having a well-tuned development experience is a huge accelerator for the individual. It turns out that individual efficiency is a minor factor when compared to collaboration.
Collaboration as a source of speed and quality
As soon as the 2nd developer joins your project, the whole thing grinds to a halt. Every change may lead to discussions. Anything you want to do may impact the other user. Emailing a zip file with _final_june3-notes-updated-by-mike_final3.zip doesn’t scale. Using a file share doesn’t scale.
It turns out that teams that collaborate well bring that individual efficiency together in a multiplicative way, yet it requires a lot of branching and merging of different streams of thought (and text).
Branching can do it all
If the only tool you have is a hammer, everything looks like a nail
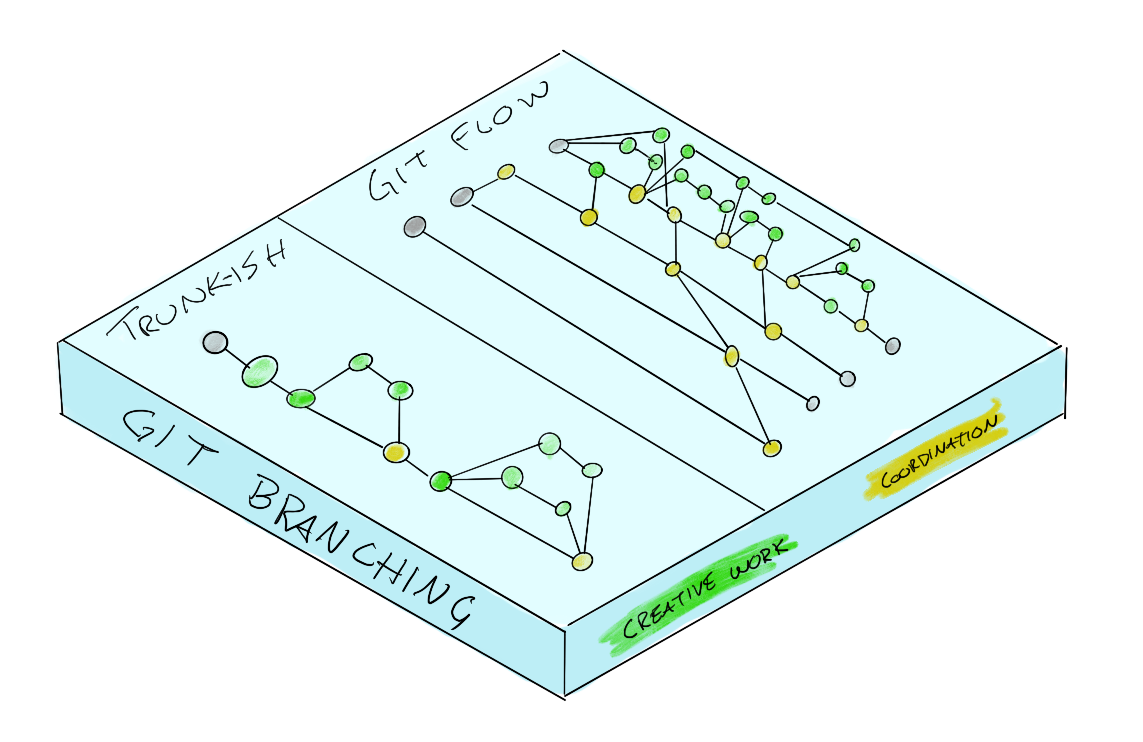
Only Git Branches and Merges
Green commits add value and capabilities, yellow commits are collaboration events.
- The trunk-ish design doesn’t have as many merges so it’s more efficient.
- The GitFlow design shows a lot of merge events which makes it more controlled.
For this illustration, the trunk-ish flow is a loose feature branch style where commits to master are acceptable and problems are caught with automation.
GitFlow looks pretty slick, only a few merges, easy
One of the methods of GitFlow that doesn’t render well is that you don’t push the merge commits until the build succeeds locally on some system. This has added complexity where a synchronous process may be necessary to merge in a few pieces of functionality. Since it’s done in a local system, the SCM server can’t help mediate the merge conflicts and test changes. The teams have to get together and work through conflicts or abandon the merge until they resolve issues.
The “trunk-ish” flow with the less controlled merge events can let a non-functional commit into the default branch which may cause trouble depending on the setup.
It’s a good thing we don’t have to stop there; enter git tags!
Going beyond branches
The GitFlow method has some mention of tagging commits that were deployed after deployment to track which commits get to which environments. This is a great idea and completely eliminates the need for that same list of commits referenced by the master branch.
The biggest difficulty with using git tags is that the regular CLI experience with managing them is very annoying. The great news is that GitLab has some handy ways to list and review tags as well as protect them so that only certain people can cut releases.
Now we can flip the workflow around and use the tags to denote when a release is ready.
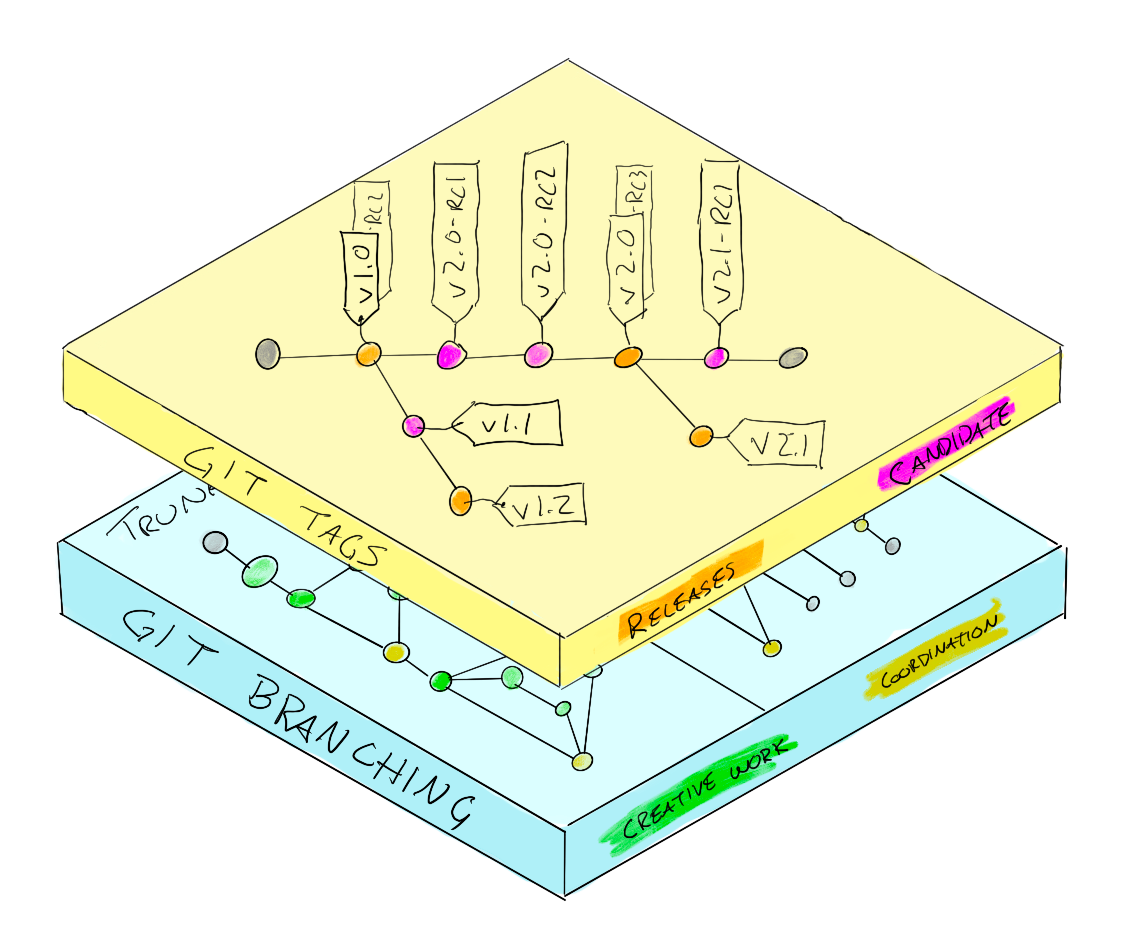
Some of them make it past RC, some of them don’t. It’s nice that you can tag a single commit with multiple tags. The other benefit here is that it doesn’t matter if you’re deploying tags from a release branch or trunk or a hotfix branch. The hotfix workflow can be to checkout a tagged commit, make a hotfix branch, deploy a patch directly from there, and then that becomes a feature branch to cherry-pick or merge back into master depending on whether that fix is still relevant in the application.
For a product that has releases and is publishing those to an artifact storage and distribution system, that’s pretty slick. Pushing out releases and ensuring any fixes make it into the ongoing developer trunk branch.
How about for a SaaS offering or an internal system with a few running environments?
Automation and environmental awareness
The last irksome thing about the way GitFlow slows down DevOps is that ops-side activity related to only allowing certain commits out in various releases creating a proliferation of release branches.
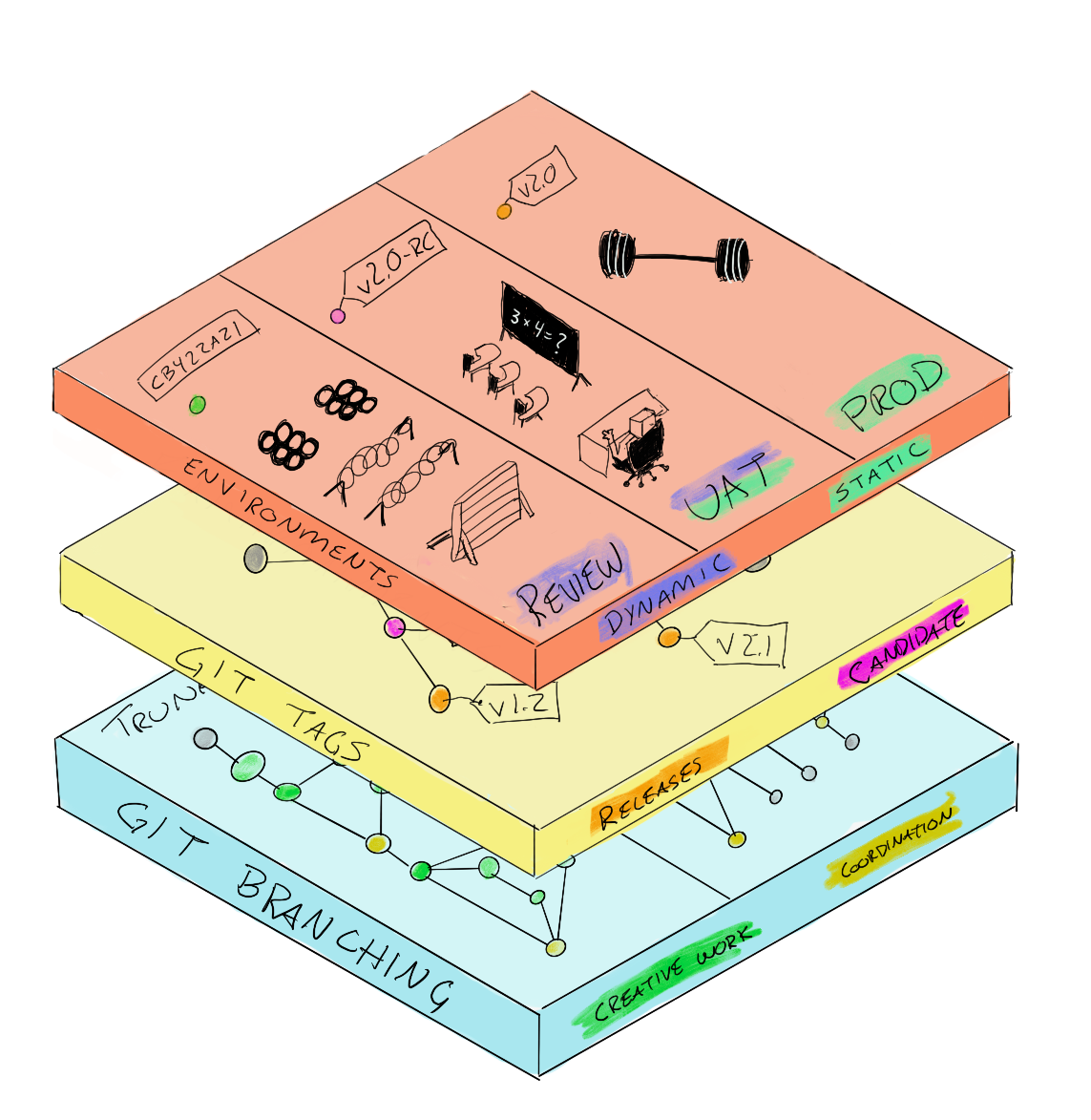
Automate and orchestrate
Every commit gets run through its paces. RC Tags get user scrutiny. Production tags get load tested and progressively deployed.
Really had to resort to metaphors for this tier, but automating what sort of automated inspections can be performed and doing so for every pushed commit is a great start. The tags are the human-supplied signal to advance the commit to the next stage. The commit hash and contents will never change which maintains consistency between environments.
Some environments may come and go, review apps may exist for each commit, each branch, or each team. Some environments will be the used for external validation or change management processes and may be persistent and require maintenance and clean-up. Of course, the production environment will be special in every case.
By including environments in GitLab, no branch is necessary to map a series of code commits to an environment.
Leverage the map of creative work, text generation, deliberate coordination, through the automation aspects.
Solving problems with git functionality
| Problem | Branch | Alternative |
|---|---|---|
| Multiplayer ad hoc | work locally and only commit finished stuff | tiny feature branches with MRs |
| Multiple features added at once | Branch per feature | Branch per aspect of the feature to keep them smaller |
| What code should be deployed? | Branch-per-release for collecting functionality which then serves as HEAD for hotfixes and patches | Merge all of what you want into a commit on the default branch and tag it. If it can’t be on the default branch due to time travel, that’s okay since tags can be anywhere. |
| What code has been deployed? | Only merge to master when it gets deployed and hope it doesn’t face a rollback or other trouble | Tag list shows patches, but you really want to see the Continuous Delivery status information |
| Multiple streams of work adding and releasing functionality | TWELVE NEW BRANCHES!? | Split up the repo into consumables and libraries, use simply workflows for each, loosen coupling. |
But our workflow is just that complicated
Another powerful GitLab option is related to splitting up large systems of components into separate repositories. Make use of features like group-level issue boards, merge request and issue relationships such as blockers, cross-project pipelines, and dozens of others.