Brownfield organizations typically have policies that were written under a very different development paradigm and create more problems than they solve under current Agile and DevOps practices.
The three security policy surface areas and related section headings in bold.
- Security verification by a security team to ensure software is secure prior to release = “Deployment interference”
- Security policies applied to developer systems and runners (endpoint and network security) = “Development interference”
- Security testing to improve the security of software during development = “Improving application security”
Deployment Interference
When “DevSecOps” is mentioned to an application security practitioner, this is the type of security they immediately think about.
Some scans belong in the pipeline because it helps the developers make better decisions, such as dependency, license, and container scanning. These have deterministic identification of validated CVEs and have a recommended fix of “upgrade to a newer version”. These scans finish in seconds and belong in the feature branch pipeline so they don’t cause deployment interference. This section covers the slow and huge scans executed by an external team which introduce delays and the findings are difficult to manage.
In compliance constrained environments the security testing approach of years past is to hand off the code at a gate review prior to being deployed. That code is scanned for compliance with some static and/or dynamic analysis rules. Feedback from that set of scans is given back to developers to remediate. This process can take a few hours but typically is weeks or months of delay and back-and-forth.
Developers eventually get the code compliant. A tiny percentage of the findings are actual security concerns. The rest are arbitrary changes to meet the rules established by the scanner. The actual security impact of static analysis scanning i. low and, due to introduced delays, delays or prevents rolling out security fixes.
This diagram shows the traditional waterfall timeline where a release is gate reviewed after some period of development, on its way to production.
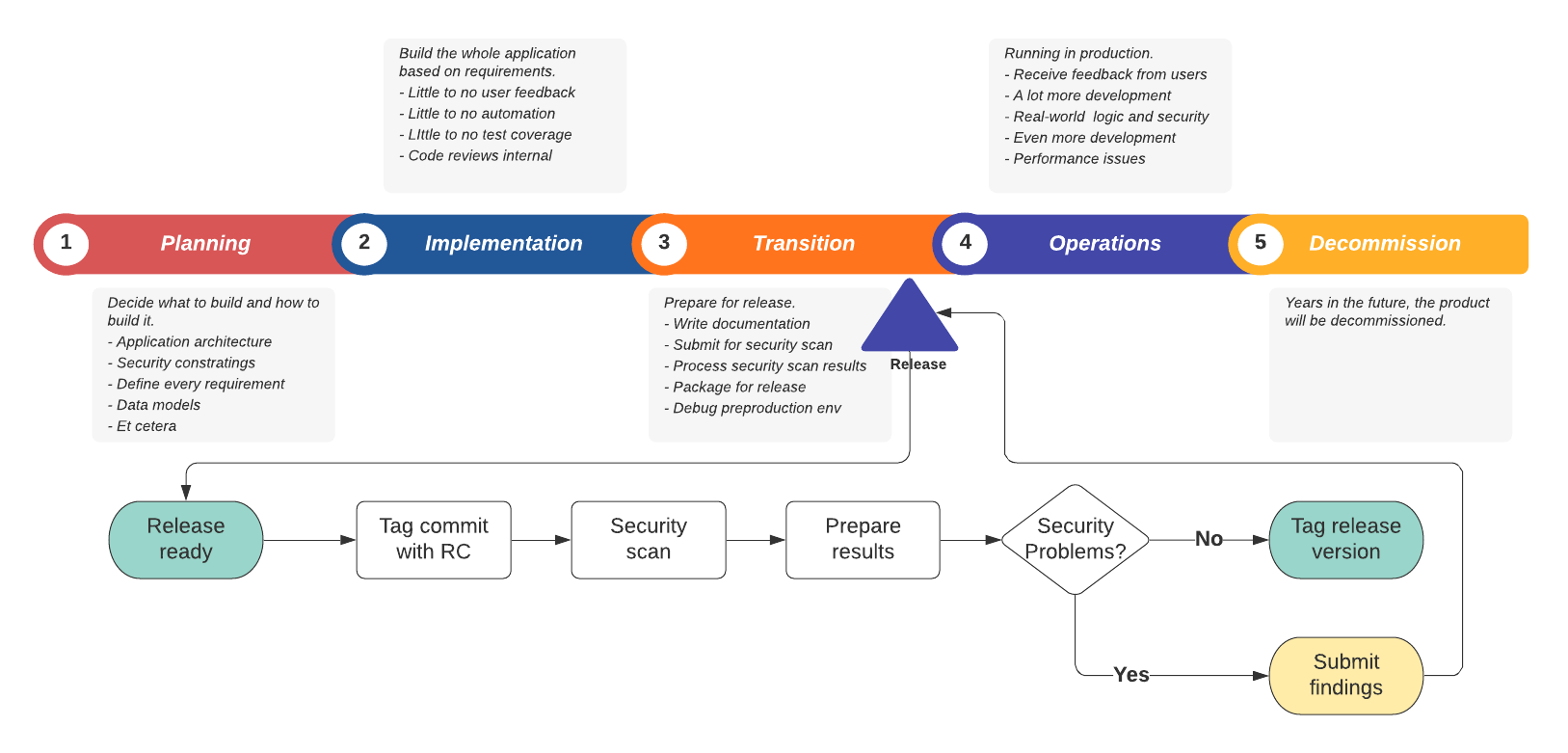
Solution
Keep this process outside the SDLC that developers experience. After some period of time using actually impactful security measures, this one will be modified to either adapt to the pace or fulfill a different purpose.
Attempts to automate this are not going to go well. It will introduce external controls into what should be a velocity and quality focused pipeline. Jobs that are out of the scope of the developer and product manager should be external to their workflow.
Recommendation:
. Use Git tags to flag a release for external verification . If external verification succeeds, re-tag the release with an actual version number . If external verification fails, remediate in the next release and start the process over
Development Interference
When “DevSecOps” is mentioned to a system administrator, this may be what they think about…
How can I keep my network and devices safe from all these development tools and security dependencies?
This topic deserves its own entire post but for now, I’ll share some guidelines:
. Use protected branches and tags with shell executors (runner and job tags are not a constraint) . Separate production system network and use tight network security rules . Separate development computers and runners from the internal network and focus on logging and DLP rather than blocking (dev systems need root) . Allow cross-network access for only services that are required (such as non-prod authentication and internal email relay) . Allow internet access to ruby gems, node packages, go packages, python packages, github, etc from development computers and runners . Use lots of kubernetes clusters for development so that each can be within the security zone of an application . Use separate kubernetes clusters for production which are locked down (can’t build or run as root, etc)
In diagram format, I’m suggesting this sort of isolation.
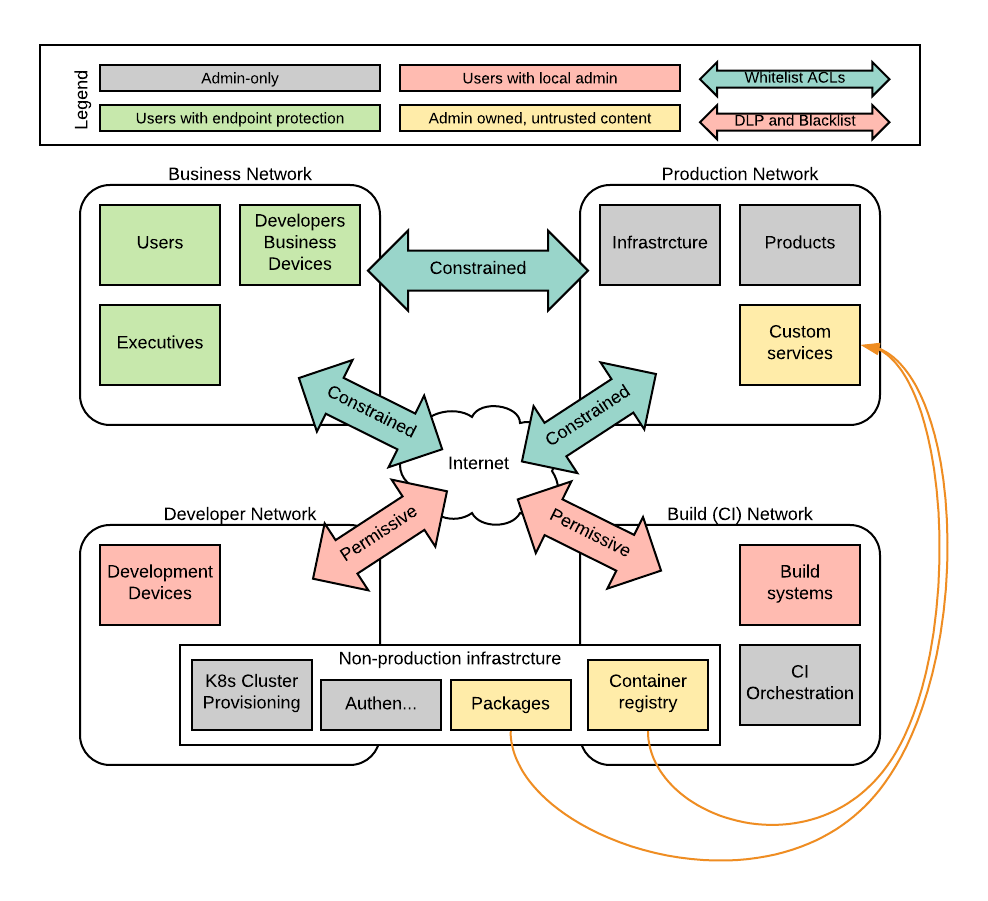
Solution
Incorporate the list from above in the architecture of the development team and provide them with untrusted systems for development and building. Don’t let production data into that untrusted zone. Only let untrusted build outputs into the trusted network through deliberate activities (such as the above-mentioned compliance pipeline).
Improving Application Security
The ideal for software development is to have the developers write code that is already secure and compliant with all of the arbitrary rules. Since the compliance scans are necessarily external to the development flow and act as a speed bump/road block, let’s put them aside and focus on actually improving security and managing risk actively.
The typical shift left approach has impacts on each SDLC phase such as:
- During planning [before code], include security review to create acceptance criteria
- During implementation [code on a branch], build security unit and integration tests, scan from the IDE . 1. Deploy to lower environments if test jobs succeed . 1. Dynamic scans and rasp and IDS and DLP evaluate what is happening during startup and execution . 1. Load testing and fuzzing and additional live tests can be done
- During approval [code merge to master], pipeline job output informs the product owner of the changes . 1. Owner sees additional dependencies and any that are outdated . 1. Owner can identify problematic licenses that may have been added . 1. Owner decides if code complexity and test coverage is acceptable . 1. Owner provides feedback on merge request if any problems worth blocking . 1. Owner can merge if it’s an improvement but still create another issue to address concerns such as complexity or tests or security
- Production packaging and deployment [commit tagged] needs to have the final compliance scan . 1. External team (possibly contractors) execute scan and provide feedback . 1. Reports can show how development velocity is impacted by compliance steps . 1. If passed, the security coordinator can approve the release and tag the commit
Since it’s the future and automation is a la mode, I would like to see the IV&V effort be entirely automated with unit tests, integration tests, and interactive testing macros.
That security coordinator can deal with the findings and help design test cases and security controls to avoid regressions. A tiny feature branch should be created to remediate the bugs. This may have to be built on a release branch and then merged into master once it’s accepted.
This hybrid diagram shows a timeline of how sprints should proceed and when a release sub-process is triggered, it will happen at its own pace.
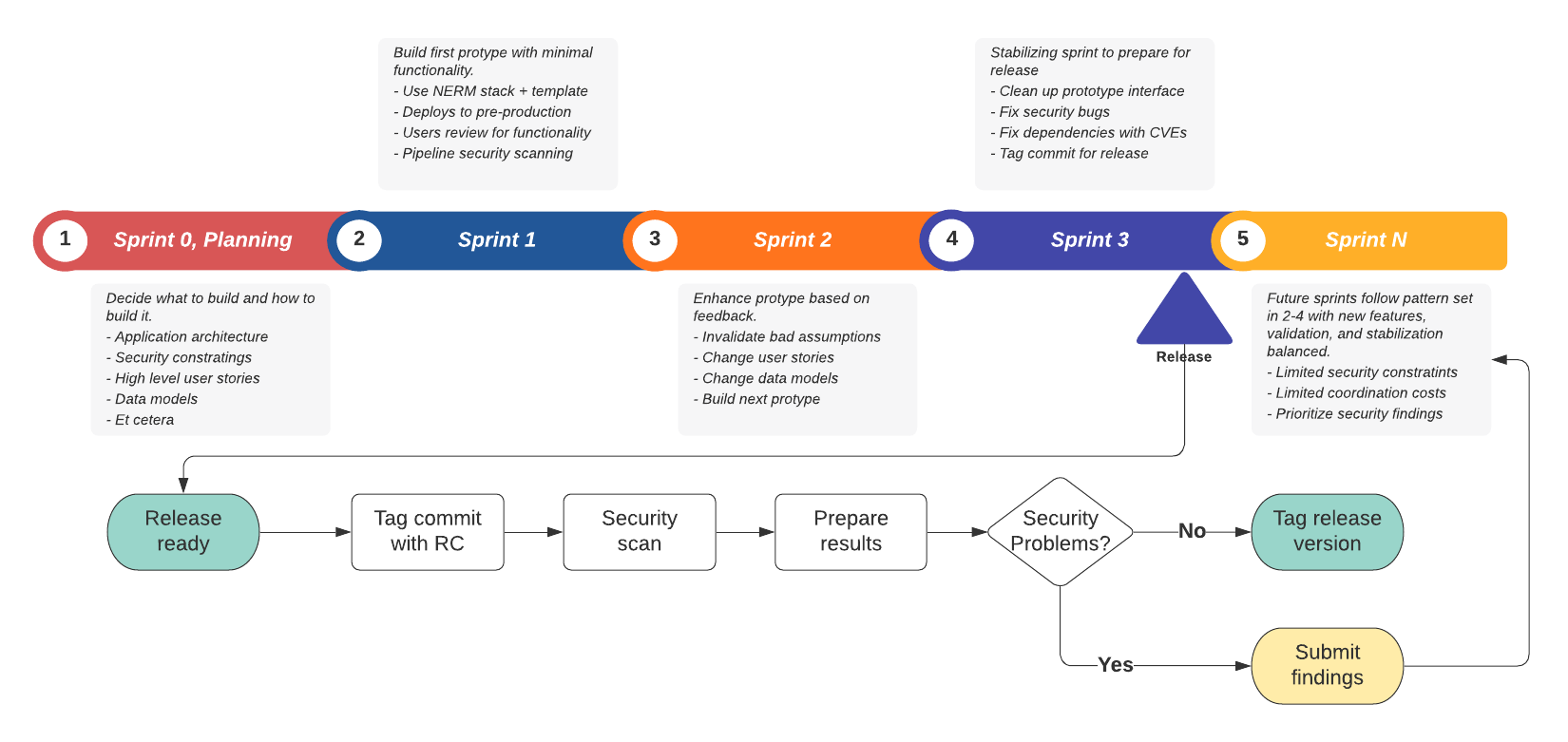
After the scanning and triage and delivery of results is completed, the project will have moved onto the next thing. If the remediation is clear a new branch should be created from that tag to finalize the release. If the tag was for v1.0 then the following command would create a branch from that tag.
git checkout -b release-1.0-fix v1.0
In some overly complex branching strategies, this is referred to as a hotfix branch. Using a merge request to coordinate the hotfix-like feature branch will make the fix to the release very clear (the branch head can be tagged v1.0.1 when ready) and ensure it gets merged into master (the point of the merge request).
Tightly coupled dependencies
One common brownfield complexity multiplier is an application with many tightly coupled dependencies where multiple teams are working in the same repository. The solution above assumes these tightly coupled dependencies can be broken out and added to their own repos and included using a package manager. The dependencies need to be given version numbers so that as they evolve, the consuming applications aren’t impacted until it is intended.
This same workflow should apply to public dependencies as used by Node and Go and Ruby apps.
Solution
Allow developers to go as fast as the product owner can support. If the team creates low quality code with security issues, they may need to be left in a compliance-heavy and slow-moving environment. This should be seen as a team failure and contracts not renewed.
Separating the external validation from the developer workflow allows the organization to be more deliberate in weighing speed vs compliance vs security. If they’re all in the same flow, it’s difficult to identify the schedule impacts of each due to the long feedback loops.
Conclusion
Shifting security left helps with actual risk posture of applications while avoiding the costly and dangerous delays associated with independent validation and verification. Keeping it right for compliance can allow incremental improvement while SDLC is updated to matc. contemporary techniques.