When transitioning from classic methods to Agile and DevOps, the gatekeepers can feel stuck in limbo. The first step to easing the transition for security reviews, change management, and independent verification is to give them a place they control. As of GitLab 13-ish, the existing roles do not meet this need, despite the merge request approval with branch, tag, and environment protections.
This article lays out a 2 project workflow with an automated merge request handoff to support the access levels needed for segregation of duties with Auto DevOps.
Overall goal: Prescriptive steps and example for Change Managers (CM)
The ultimate point of this exercise is to give the change management people something to point to that can guide their decision-making and planning. DevOps activities are often relegated to the creative side of the SDLC and when it comes to deployment, the change management process grinds it to a halt. This proceeds one of two ways:
- Developer team overwhelms CM by executive mandate, CM feels like they can’t validate
- CM team overwhelms the business needs pushing for reliability and security over velocity, developers feel thwarted
Both of these outcomes negatively impact the organization’s culture. Successful transitions feature a shift toward a collaborative way of working where the Change Managers refocus on the processes and automation. The problem is that everyone has jobs to do and redesigning the whole change process and restaffing with automation experts or training the existing team is rarely prioritized. Experience has shown the low priority is due to the unknowns and risk averse nature of change management.
This whole example group and documentation and video walkthrough is an attempt at providing some first steps that don’t leave either team in a lurch while adding visibility and incentivizing automation. This should lead to the cultural changes that really enable DevOps and agility.
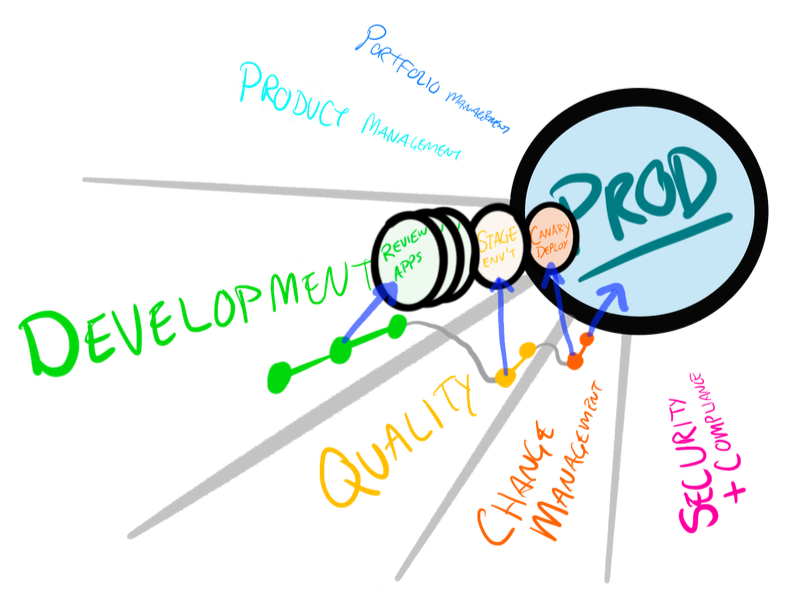
Expected outcomes
A team that moves from a classic waterfall deployment to this two-project workflow will experience benefits as their processes tend toward DevOps. The initial iteration is mostly replicating the waterfall. It places easily-automated gates in as manual tasks and approvals to get started.
After a few iterations and task automation, the following benefits will show up. Any that don’t show up will at least be reflected in metrics to help identify where to focus scrutiny and make further changes.
- Consistent interactions within and across teams (issues and merge requests)
- Few ingredients enable everything (GitLab, CI yaml, shell scripts, containers)
- Analytics and insights to provide visibility into the whole workflow
- Gamified automated test coverage, security scans, quality analysis
- Automated deployment and Infrastructure-as-Code, metrics collection, automated rollback
None of this is “the right way to do” anything, it is one way to use GitLab to create familiar thresholds.
The next few sections talk about why this approach is needed. Then delves into the workflow and describes the specific jobs.
It’s important to know what limitations in GitLab lead to this workflow since they will be resolved at some point in the future in some way. That way may be better than this, it may not. The fact that the product gets measurably better every month means this may not be good advice for long.
Developer and Maintainer roles don’t map to enterprises
GitLab’s Developer and Maintainer roles match the Open Source contribution model but have too much of a gap for enterprise workflows. A developer can’t be an effective product manager since it can’t configure pipeline variables or project membership (among other things). Likewise, a maintainer can impact both the code and production deployments.
This conflicts with Segregation of Duties which is required by many enterprises and public sector organizations.
This is a work-around
If your organization doesn’t require this, keep it all in one project. The feedback loops are better within a project. The Maintainer being responsible for deployments is actually a good pattern where they can positively impact the running production system since they have skin in the game. The idea that Change Management teams need to be injected into the path to production is predicated on legacy systems being unable to adopt “newer practices” and automation.
The “newer practices” are things like localized data and decoupled service which orchestrators can manage compatible version upgrade and roll back automatically. If your teams still use a huge central database or have applications running inside that data layer, this workflow will provide visibility into what that actually cost to maintain that over time.
GitLab’s possible solutions
It’s unlikely that GitLab will implement custom role definition within the product. It adds a lot of complexity while only benefiting a small subset of compliance-minded users.
The most likely solution would be to allow a group owner to limit certain permissions from roles in various projects. This would make the group owner or maintainer role the over-powered one and the project maintainer could be a product owner who can’t impact production. The problem here is that the person who is a group owner can overrule everything below them and ultimately violates segregation of duties anyway.
The good news is that GitLab is very innovative and solves tough problems creatively so there may be some great remedy around the corner that I haven’t anticipated. If you’re reading this well after publishing date, be sure to check the GitLab documents and release notes for custom roles and policy framework.
The workflow
Please take a few minutes to watch the video that shows the workflow.
For the example, the Auto DevOps workflow was selected since it provides build, test, secure, review, stage, and deployment jobs out of the box. The example basically starts from the most DevOpsy approach and brings in the classic waterfall gates.
- Developer makes a branch and commits new features to it
- Developer creates a merge request for code review, test results, etc
- Product stakeholders (security, team leads, SMEs) approve merge
- Product owner or delegate merges into default branch
- Merge Event or Release Tag triggers hand-off job rather than production deployment
- Independent testing approves the Deployment project merge request
- Change management merges to default branch
- Pipeline on default branch deploys to production (or queues the manual deployment job)
In a DevOps workflow, the independent testing and change management approvals would happen as part of the merge request approvals in step 3. It is split out here to create a hard constraint rather than relying on the participants to follow review policies.
This is mainly for pre-DevOps teams to transition
In a DevOps paradigm, the change managers would only scrutinize the parts of the project that relate to the rollout and rollback automation since anything else can self-heal. There may be a security review, but that would be part of the merge request as well. Since the product owner and developers are on call, their interests are served by maintaining security and reliability as well as the functionality improvements.
The good news about using this 2 project approach is that it leads to automating everything anyway. As the independent testing and change management teams begin to feel more like a rubber stamp, they can remove their manual gate and use jobs to validate the sensitive parts. If they create a script to diff the parts of the repo that impact rollout and rollback, the deployment merge request can be created with merge when pipeline succeeds and only require human involvement when that pipeline doesn’t succeed.
The other cultural enhancement here is that everyone can see the pace at which MRs are sent across for release and the pace at which they’re tested and released. The effectiveness of these gates can also be tied to issues and MRs. If the application team is trying to release poor quality software, the stage MR will show a lot of activity. Alternatively, if the testing or validation or deployment teams are inhibiting the workflow without providing sufficient value, that delay is quantified and can be iteratively improved and experimented upon.
So what does it look like?
As was shown in the video walkthrough, the group and projects start with Auto DevOps and deviate in important ways.
This group is a proof of concept of this workflow. It is undergoing refinement as various public sector customers implement some version of it to mitigate the role mismatch. This specific example uses Auto DevOps as a baseline and overrides the parts needed to support this workflow.
This table contrasts the Auto DevOps stages and job types with the Segregation of Auto Duties (SoAD) items from each project.
| Auto DevOps | SoAD: Spring Web App | SoAD: Deployment |
|---|---|---|
| Build | Same | Replaced with get artifacts job |
| Test | Same | Replaced with validation placeholder |
| Review | Same | Not present |
| DAST | Same | Not present, though could be run against staging |
| Performance | Same | Not present, though could be run against staging |
| Staging | Not present | Configured to work more like Review (dynamic environment name) |
| Canary | Not present | Optional but not in example |
| Production | Not present, handoff job instead |
Same with example set to manual |
| Incremental rollout | Not present | Could be used as a rollout strategy instead of manual |
The stages in this table are not linear for every pipeline. The merge request pipelines stop at performance and have cleanup jobs. The default branch jobs have some different names and include the production or incremental roll-outs.
Pipeline graphs at time of first publishing
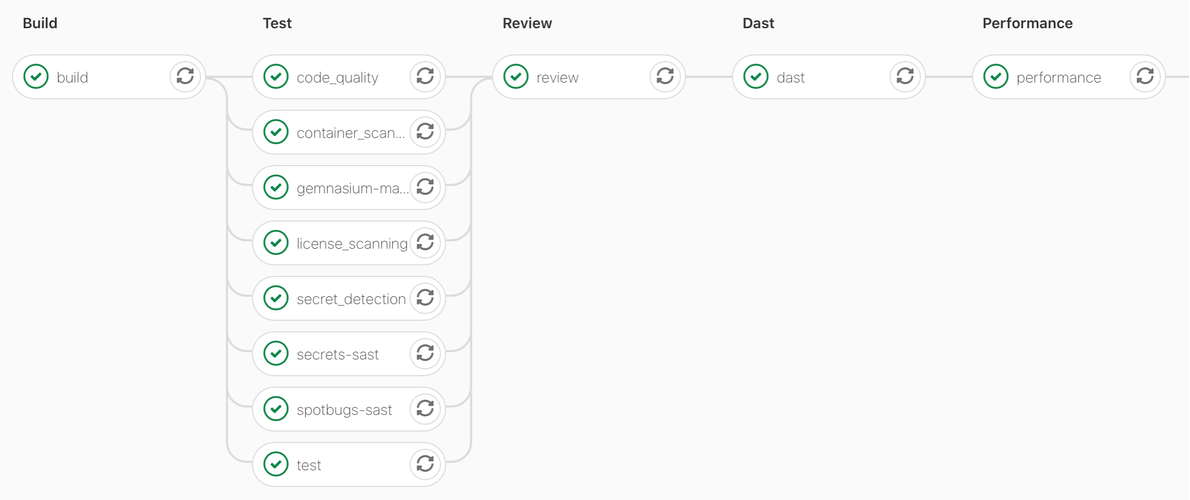


Deploy project Merge Request commit pipeline
Features the get artifacts job to feed artifacts into Auto DevOps for staging app deployment

Deploy project default branch pipeline
Uses the same get artifacts job to run the production deployment
What are the jobs and what do they do?
There are 2 important activities that aren’t in the regular process. One is the handoff job where the Spring Web App pipeline creates a Deployment project Merge Request (with updated reference). The other is the Deployment project receiving the updated reference and acting on it.
I talk through these jobs at 9:50 in the video walkthrough
Handoff jobs to create a merge request and commit
This encompasses 90% of the work since GitLab itself handles the notification and collaboration of the merge request workflow. In the example (as of now) it’s split into 2 jobs, one for the Lab Assistant part which creates a branch and merge request and assigns it to a specific user.
Then a second job which runs some curl requests to make a commit with the updated container reference.
Since these are defined in the pipeline, the rules and other aspects are customizable to your heart’s content. The example shows a tag as the event to support other branching and merging and release strategies, but you can update the rules to create these jobs as automatic or manual for any branch or tag design you like. More on that below.
Get artifacts job to pass environment variables down the line
In the regular Auto DevOps pipeline, the later jobs use variables related to the project, branch, and git commit hash to deploy or scan artifacts created earlier in the pipeline. The Auto Deploy Image happens to use these environment variables only if another set of variables is not used. The CI_APPLICATION_REPOSITORY and CI_APPLICATION_TAG, if found, will be used instead of the repo and tag that started the pipeline.
The get artifacts job runs first for every pipeline in the Deployment project and uses a recently added artifact:report:dotenv feature to send those environment variables into the remainder of the pipeline.
The handoff:commit job creates or updates the artifacts.txt file so this job deconstructs it. An improvement could be to set the contents of the artifacts.txt file in the first pipeline to the output needed for the dotenv report and then this job would just cat that file into the log for troubleshooting purposes.
get artifacts:
stage: handoff
script:
- |
(echo "CI_APPLICATION_REPOSITORY=" "$(cat artifact.txt | cut -f1 -d:)") | tr -d '[:space:]' > artifact.env
echo >> artifact.env
(echo "CI_APPLICATION_TAG=" "$(cat artifact.txt | cut -f2 -d:)") | tr -d '[:space:]' >> artifact.env
artifacts:
paths:
- artifact.env
reports:
dotenv: artifact.env
While building and testing this, the .auto_deploy stub which is extended into the deploy jobs in Auto DevOps had dependencies: [] added to it which stopped the dotenv report from showing up. If this optimization is rolled back, it makes the overrides easier but the regular pipeline less efficient.
But why tagging instead of merge?
This was arbitrarily setup to show an example of how a release can be organized without sending every single merge to the deployment project. There may be too much noise if every merge triggers a new merge request, so adding this deliberate tag event with a protected tag allows the product side to pile up a few features and then release them together.
The only change necessary to move the handoff jobs to the merge pipeline is to change the rules.
The default git tag approach:
rules:
- if: '$CI_COMMIT_TAG =~ /^v/'
when: always
- when: never
The default branch approach on every commit:
rules:
- if: '$CI_COMMIT_BRANCH == $CI_DEFAULT_BRANCH'
when: always
- when: never
The default branch approach but manual:
rules:
- if: '$CI_COMMIT_BRANCH == $CI_DEFAULT_BRANCH'
when: manual
- when: never
This can also be combined with “environment” and a protected environments to limit who can trigger the handoff job. This is configurable by any maintainer so the merge to default event would have the same threshold as the protected environments.
This seems really complicated
In delivering this information to various groups, it’s definitely got some complications to it. The majority should be hidden within Lab Assistant or a shared include that provides a consistent handoff experience across your portfolio of applications that need Segregation of Duties.
A large amount of the pipeline is from Auto DevOps so using your own may lead to a much simpler build, test, handoff, merge, deploy sort of pipeline.
I walk through the path to production part in 9 minutes in the video walkthrough. The issue management, oversight, and other aspects of the SDLC work like regular GitLab functionality but with the cross-project aspects leading to using more of the group level interfaces.
Feedback loops are disconnected
Yes, this is suboptimal in terms of GitLab’s native project-level analytics and insights. The best way to leverage this approach for permissions while still maintaining visibility and collaboration is to use a group (or subgroup) for these projects.
Several group level features mitigate the disconnection, as long as users can see the other projects. Everyone who interacts with this application should be a developer at the group level, then as needed upgraded to “maintainer” in the specific project. The group owner would need to be someone from access control since they’d be able to impact segregation of duties.
The group level supports:
- Epics for cross-project coordination
- Issue boards for planning work that spans projects
- Merge request view into ongoing work
- Analytics and insights
- Security and compliance reports
Cross-project collaboration is a good thing to be doing anyway
It’s rare that an enterprise application fits nicely into a single git repository and since the relationship in GitLab is 1 project : 1 repository, many applications have many projects.
GitLab itself had dozens of repositories in addition to the core rails application repo. There are repos for Omnibus and Cloud Native for distribution, a runner project, a docs project, a few quality projects, a few dev tooling projects, a cluster integrations group full of projects for various images and charts, and dozens more. Work crosses these boundaries for most developers on a daily basis.
Adding another project full of Infrastructure-as-Code for deploying an application is also common, so that would be the logical place to target the merge requests created by the handoff job.
Getting started
Watch the video walkthrough first.
Head over to the Segregation of Auto Duties group and see what the current state looks like. There should be a friendly README.md to point you in the right direction.
The two aspects to work through are:
- How many protected branches, tags, merge requests, etc are needed? (minimal gates)
- What data needs to be handed off? (minimal handoff)
Then you can apply these patterns to your workflow.
Feedback is always welcome!
Please scrutinize and suggest fixes and enhancements to the design or projects or workflow.