Coder recently made their enterprise offering free for up to 10 developers. Since my solution, which I will henceforth call “ICSW”, supports 1 developer, it is well within that limit. I configured a new namespace in the same cluster to run the Coder Enterprise system to see how they compare.
TL;DR: Coder Enterprise has a lot of benefits for centrally managed code-server deployments as well as a multi-image workflow.
So to expand a bit on the TL;DR, the benefits of Coder Enterprise are mainly apparent in three places:
- Tying into enterprise infrastructure for authentication, image storage, etc
- Standing up new images is trivial, even images that don’t have code-server on them can be started and run since they created a builder that adds the necessary stuff
- Managing governance and access controls
Workflow phase 1: decide and define what to run
For any developer workflow, the first step is to decide what to run and get the tools organized. In the classic approach, the hardware is defined by your device at hand, and then software descends from the operating system. This can impact stack selection to some degree.
Pragmatically, in enterprises we are handed a stack and existing things to build from and integrate with. The tools are selected and we do our best to align the software development.
For the case we are defining here, the stack could be anything that visual studio code can handle. I am also sticking to my hardware-at-hand constraint of iPad Pro to avoid more variables.
- Classic workflow: Install software on your device
- ICSW: Create a Dockerfile and modify the
code-server.yml - Coder: Pick an image that already exists (creation is out of scope)
ICSW specs include all of the things ranging from the image to the ingress and services. These can be split or individually tuned later, but every time is a trip back to the kubectl command.
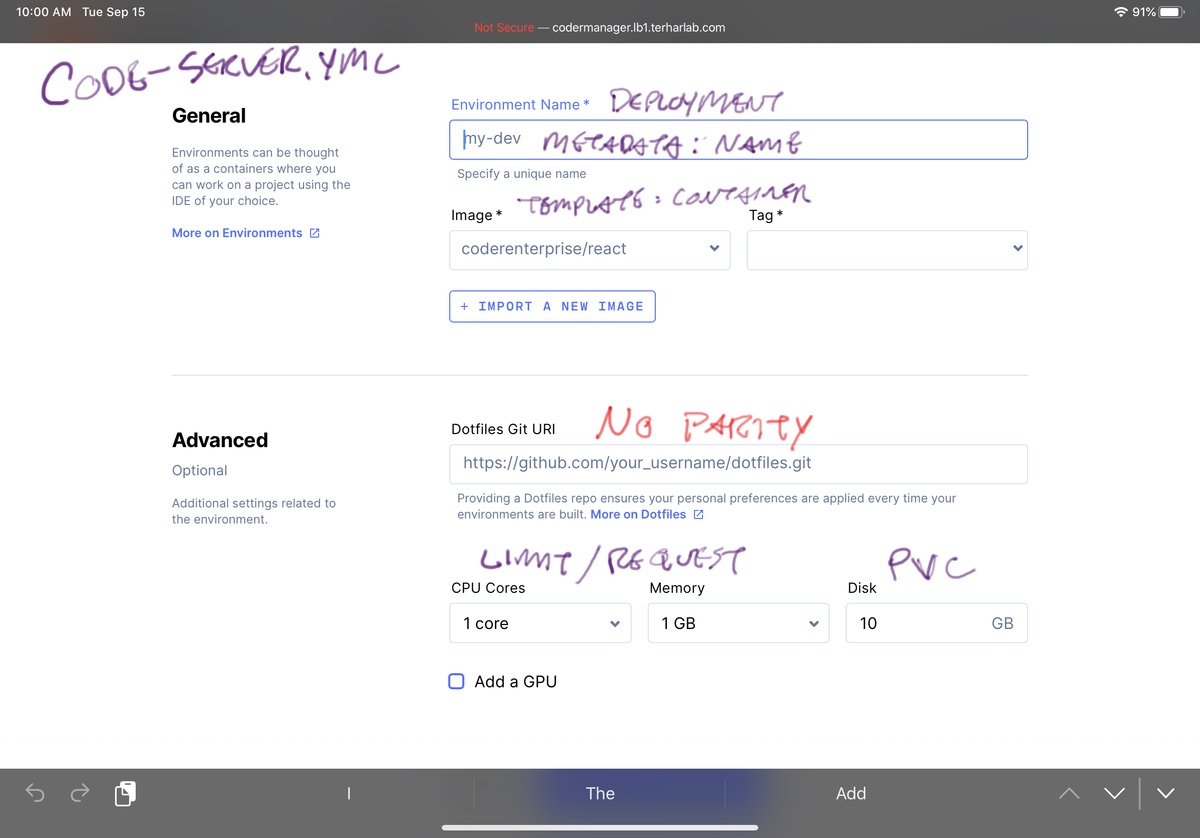
You don’t have to make all the decisions up front in the Coder environment configuration. This has benefits in terms of low friction to get started. The additional option here to select dotfiles from a git repo is another multi-user quality of life enhancement.
In ICSW, there is only one home directory that I bring from image to image so my dotfiles are always there. This would present issues if I switch to incompatible versions or even change from bash to zsh in some images. Also it prevents me from starting up 2 or 3 images at once with my configuration since the persistent volume can only be mounted to a single image at any given time.
The other massive deviation here is that ICSW creates RBAC objects related to this environment but not related to a specific user. Coder’s authentication provider has tie-ins with the image creation process, the image start-up process, and even connecting to private git repos for the dotfiles.
This also replaces the password authentication when first accessing ICSW with the same authentication and authorization as accessing the Coder Enterprise management web app.
My cluster, my rules, but mutlti-tenancy with ICSW would be inherently trusty and Coder is much less so.
Workflow phase 2: starting up the image
Like most kubernetes-direct activity, applying the code-server.yml file will hit the API and report back a boolean of “changes?” for each object. Most will come back “unchanged” except for the updates or creations.
Once the kubernetes specs are in, Kubelet starts to actually get stuff organized. The approach for a human inspecting profress on scheduling and initiation of the code-server pod is to usual loop of:
kubectl describe pod code-server-383289 -n development
kubectl logs code-server-383289 -n develpoment
[up up enter]
[up up enter]
And on and on until you can hit the ingress and get to that password prompt.
This is honestly one of my favorite things about Coder Enterprise, it actually shows what’s going on inside the pod!
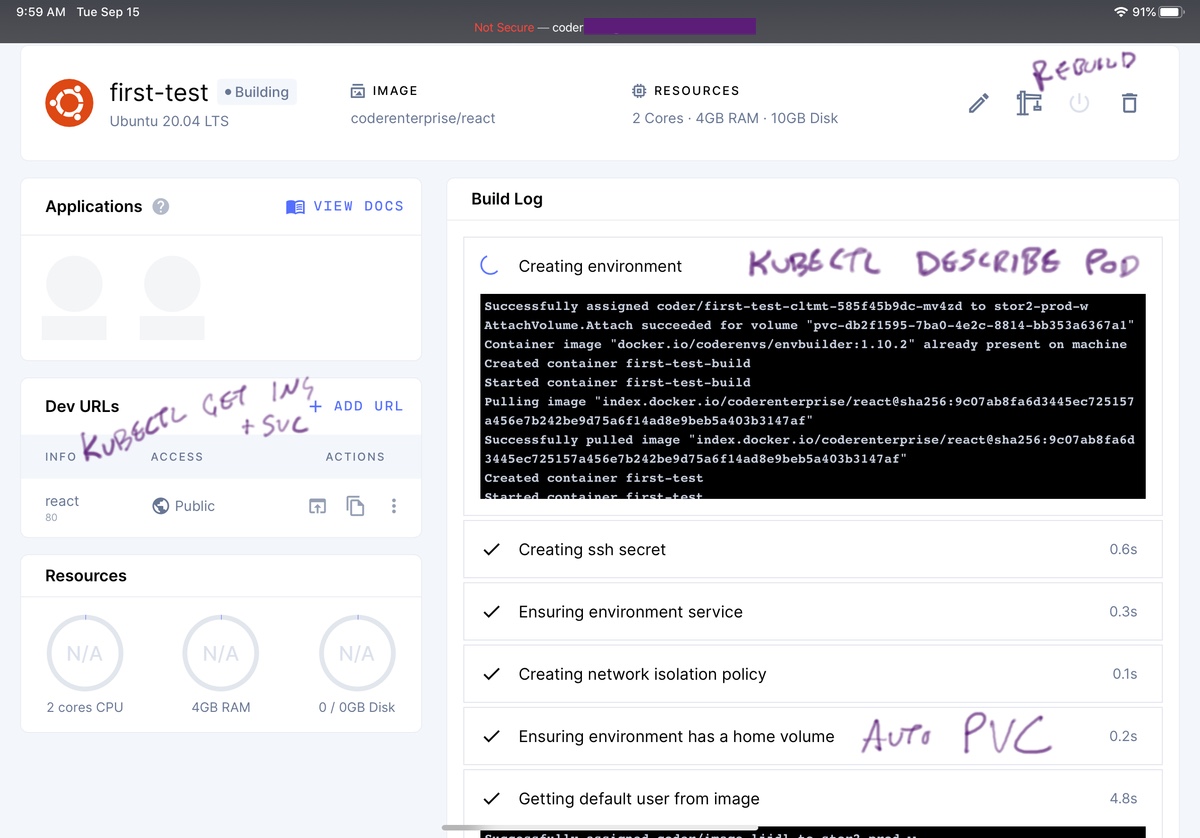
Since it runs through a dozen or more initialization and configuration steps, lacking visibility into this would be torture. The interface for this is a delight. New blocks pop in for each new step. Logs come back where appropriate. Operations are timed to help set expectations of when stuff is going awry.
Workflow phase 3: operating the thing from an iPad
So there is very little difference once the system is running. The approaches both use the same code-server image that Coder publishes. No secret withheld capabilities.
Coder has the same shortcomings as the ICSW as mentioned in the problems section of the initial article with one exception. “Docker build steps are not allowed inside my Kubernetes cluster…” is obviated by the init container adjusting the images on the fly as it’s provisioning them.
Rather than giving control of the namespace to the image itself (by way of secret in the PV), the Coder manager web app is perfectly functional from a mobile browser and provides all the rich controls and visibility I talked about above. It also creates the ability to recover from a spec change that damages the code-server pod or other configuration. If I accidentally set an ingress port or service name wrong, it could knock me out of the image and I’d have to resort to SSH and kubectl.
Governance and access controls
The best part of Coder Enterprise for Brownfield organizations is that authorized individuals have boundaries enforced around their running containers.
Images cross this houndary in the way into an internal registry where they can be deliberately cleaned and approved as they are made deployable with Coder. There’s also a “deprecate” option for images that need to remain in service to avoid disruptions but shouldn’t be used going forward.
Developers cross the boundary when accessing their development environment. The ability to control ingress and egress, DLP tools, and allow open-source-libraries within this boundary makes security easier. This protects both the business network and the production network.
It lets the Coder and runner clusters act like a construction site full of dangerous heavy equipment. The delicate business purposes are insulated from the experimental nature and risks inherent with development tools.
There also seems to be a bit of spyware or performance management baked in, though I didn’t put a lot of attention on those. I’m sure they could be misused, but so can other logging and monitoring systems.
Roadmap item highlight
There’s a roadmap item for multiplayer code-server. I’m not sure if that implementation is for code-server or Coder Enterprise but it’s gonna be powerful when they get to it.
On installation; or why Helm doesn’t help
Above I charitably start the “provisioning” step for Coder at the point where it is already installed whereas ICSW is completely absent from the cluster and the spin up of all the pods and pulling of all the images happens at that point.
Like most enterprise solutions aimed at Kubernetes these days, it uses Helm. Helm is a templating engine that takes a simple command line and deploys complicated multi-pod systems with lots of dependencies and things… Except that it doesn’t deploy things most of the time. It silently errors out and you’re left scratching your head.
What it ends up doing is hiding the clear and descriptive kubernetes API yaml files and instead shows the consumer either a command line with a few options or a values.yml file. The values may or may not be consistently applied throughout the various templates, because the template syntax is painful to try to decipher. So now in exchange for fewer lines of configuration, you have reduced visibility into change, reduced ability to reason about what resources may be required, and a disadvantage at troubleshooting time.
This isn’t an indictment of Coder, the GitLab cloud native deployment uses Helm. Also, operators aren’t some magic solution because even the Mattermost Operator requires a lot of futzing to get working and the GitLab Runner Operator is missing a bunch of options and configurations as of this article’s publish date.
From what I can tell, Kubernetes is only good for publishing your own software or getting knee-deep in yaml specs to deploy and then be able to reason about and keep running on day 2.
Also, it bothers me that every Kubernetes thing uses yml for the extensions for yaml files, except Helm uses yaml for the extension.
Any system administrators who are installing Off-The-Shelf software using helm and are comfortable with it, let me know…
I don’t like it.